Python w wycenie nieruchomości
Po dłuższej przerwie we wpisach chciałbym Państwu przybliżyć w jaki sposób można wykorzystać język python w codziennej pracy rzeczoznawcy majątkowego. Obstawiam, że większość z rzeczoznawców wykorzystuje poczciwego Excela w trakcie sporządzania operatu szacunkowego. Co jest mniej lub bardziej efektywne? Na to pytanie będą musieli Państwo odpowiedzieć sobie sami. Z pewnością za pomocą pythona możemy usprawnić sobie pracę i wzbogacić swoje opracowania o dodatkowe analizy wykonane w krótszym czasie.
W tym wpisie nie będę poruszał samej kwestii instalacji pythona i narzędzi wymaganych do pracy. W internecie znajdą Państwo materiały, które opisują cały proces instalacji. Do zadań prezentowanych przeze mnie w tym wpisie będziemy potrzebowali pythona w najnowszej wersji oraz narzędzia Jupyter Notebook, w którym to będziemy pisali nasz kod.
Ceny mieszkań Wrocław
Czym się zajmiemy? Zajmiemy się analizą rozkładu jednostkowych cen transakcyjnych lokali mieszkalnych. Przedstawimy rozkład w postaci histogramu, porównamy go z rozkładem normalnym oraz wskażemy podstawowe miary takiej jak średnia, mediana oraz dominanta. W jakim celu to robimy? Na podstawie takiego wykresu będziemy w stanie stwierdzić jak wygląda analizowany przez nas rynek, jaka jest najcześciej występująca cena za metr kwadratowy, a te, które najbardziej dostają od tej wartości będą przedmiotem dalszej analizy. Być może zachodzą wśród niech przesłanki do określenia tych transakcji jako nierynkowe i odrzucenia ich w dalszej procedurze wyceny.
Zatem do dzieła. Po otworzeniu nowego projektu w JupyterNotebook musimy zaimportować niezbędne biblioteki, z których będziemy korzystać. Zrobimy to za pomocą poniższych linii kodu:
import pandas as pd #umożliwia pracę z plikami excel i tworzenie obiektów data frame
import numpy as np #wspomagające obliczenia matematyczne oraz pracę na wektorach
import matplotlib.pyplot as plt #umożliwiająca wizualizację danych
import statistics #obliczenia miar statystycznych
Kolejnym krokiem będzie wczytanie danych, zrobimy to za pomocą poniższej linii kodu:
dane = pd.read_excel(r”ścieżka_do_pliku_excel”)
Możemy sprawdzić załadowane przez nas dane transakcyjne nieruchomości za pomocą:
dane.head() # wyświetli to nam 5 pierwszych wierszy wczytanej zmiennej dane
Następnie za pośrednictwem wymienionych przeze mnie bibliotek powyżej stworzymy histogram dla analizowanych transakcji. Dodatkowo naniesiemy wykres dla funkcji gęstości prawdopodobieństwa rozkładu normalnego oraz średnią, medianę i dominantę analizowanych przez nas cen jednostkowych mieszkań.Histogram cen transakcyjnych stworzymy dzięki bibliotece seaborn, a dokładnie za pomocą modułu distplot. Przykład użytego przeze mnie kodu:
hist = sb.distplot(kol_anl,bins=np.arange(round(min(kol_anl),-3), round(max(kol_anl),3) + binwidth, binwidth),norm_hist=True)
Pod zmienną kol_anl znajduje się wybrana kolumna z cenami jednostkowymi z załadowanych przez danych (zmienna dane). W tym momencie posiadamy histogram przedstawiający nam jak często dane ceny transakcyjne występują na analizowanym przez nas rynku. Co ważne zmienna norm_hist ustawiona jako True ukazuje nam częstość występowania cen nie jako konkretną ilość, a jako prawdopodobieństwo. Zatem suma częstości występowania cen transakcyjnych będzie równa 1 (100%).Dodajmy teraz wykres funkcji gęstości prawdopodobieństwa rozkładu normalnego, tak aby porównać go do naszego histogramu. W tym celu musimy najpierw stworzyć próbkę danych oraz zestandaryzować tę próbkę aby jej rozkład był rozkładem normalnym o średniej i odchyleniu standardowym identycznym jak badana przez nas próbka jednostkowych cen transakcyjnych nieruchomości.
x = np.linspace(port_mean - 3*port_stdev, port_mean+3*port_stdev,500)
plt.plot(x,scipy.stats.norm.pdf(x,port_mean,port_stdev),"g--",label='rozkład normalny')
Zmienna x zawiera 500 obserwacji, z której najmniejsza wynosi średnia - 3*odchylenie standardowe, a największa średnia + 3*odchylenie standardowe. Przy czym średnia i odchylenie standardowe są obserwacjami z pierwotnie badanego przez nas rozkładu. Dzięki funkcji scipty.stats.norm.pdf standaryzujemy rozkład reprezentujący nasze 500 obserwacji, a dzięki pkt.plot nanosimy go na histogram. Poza wyżej wymienionymi elementami naszego wykresu dodajemy średnią, medianę oraz dominantę. W rezultacie powinniśmy otrzymać wykres wyglądające tak:
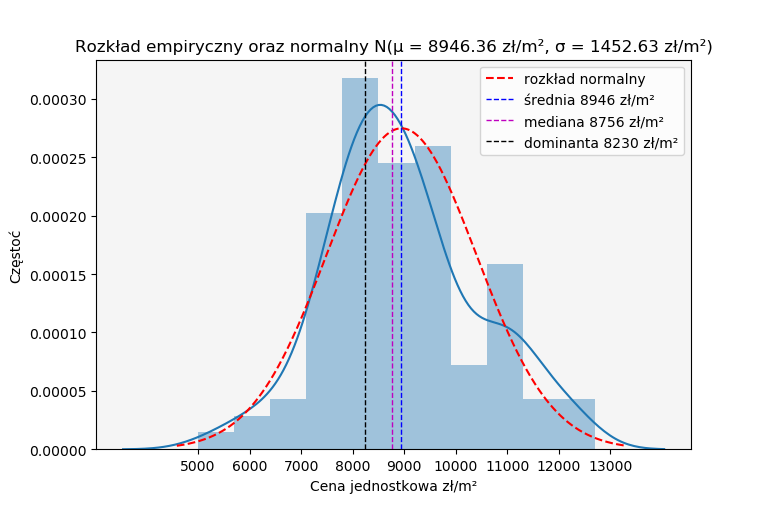
Tak wyglądający wykres możemy załączyć do operatu szacunkowego jako element analizy rynku. Z pewnością wzbogaci on nasze opracowanie. Dane zaprezentowane w formie graficznej są cześciej zapamiętywane od tych zapisach surowym tekstem.
Z przyczyn oczywistych nie zamieszczałem pełnego kodu na stronie. Jeżeli ktoś z państwa będzie miał problem ze stworzeniem podobnego narzędzia do analizowania rozkładu danych zapraszam do kontaktu.
W kolejnych wpisach będziemy poruszali inne aspekty wyceny nieruchomości, w których rzeczoznawca majątkowy może wykorzystać języki programowania. Oczywiście nie będziemy się zabierali za pełną automatyzację wyceny - choć jest to ciekawy temat do dyskusji. Skupimy się raczej na analizach niezbędnych do wyceny nieruchomości w podejściu porównawczym oraz dochodowym.